Regex Nedir ve Neden Önemlidir?
Bu metinde her yazılımcının bilmesi gereken Regex'i inceliyoruz.

Düzenli İfadeler (Regex) Nedir ve Neden Önemlidir?
Düzenli ifadeler (Regex), metin içinde desenleri tanımlamak ve aramak için kullanılan güçlü bir araç. Regex, metin içinde belirli desenleri tanımlayan ve eşleşen metinleri bulmamıza yardımcı olan özel bir karakter dizisidir de diyebiliriz.
Peki Regex’i neden öğrenmeliyiz?
Aslında sebebi çok basit… Regex, string değişken içeren her yerde kullanabileceğiniz bir ayıraç. En güzel kısmı ise, şu anda size popüler programlama dillerini sorduğumda aklınıza gelen tüm dillerde Regex’i anlayabilirsiniz. Bu sebeple Regex’i iyi bilen biri, string veriler ile hiçbir problem yaşamaz.
Regex nasıl çalışır?
Sizin verdiğiniz ifadeleri, istediğimiz string verisinin içinde önce karakter karakter gezerek, sonra verdiğimiz ifadenin tamamı ile eşleştirerek, eşleşen verileri; (eşleşenlere "true", eşleşmeyenlere "false" şeklinde) bize geri döndürür.
Gelin örnekler üzerinden inceleyelim.
İlk olarak, Regex’i 2 adet slash(/) tuşu ile tanımlayabilirsiniz yani /blablabla /
Ve bu fonksiyonu, bazı yazılım dillerinde olduğu gibi yazabilirsiniz. Ancak, bazılarında fonksiyon girdisi olarak kullanabilirsiniz; yani, RegExp('regex', 'flag') gibi... Üzerinde çalıştığınız yazılım diline ve regex fonksiyonuna bakarak, nasıl çalıştığını hızlıca kavrayabilirsiniz.
Regex'te bazen belirli özellikleri devreye sokmak isteriz; örneğin, 1'den fazla seçsin, büyük küçük harfi dikkate almasın, satırları dikkate almasın, Türkçe karakterleri içersin... Bu özellikleri belirlediğimiz alana "flag" diyoruz. Örneğin: /blablabla/gmis.
Şimdi hızlıca flag'leri açıklayalım, ardından Regex'in içeriğini anlatmaya başlayabiliriz.
g (global): En yaygın kullanılan flag'dir. Birden fazla "true" dönen (eşleşen) ifadeleri seçer. Ancak, Regex genellikle her yerde %95 aynı şekilde çalışır, fakat bu %5'lik fark sizin bir saatinizi veya belki bir gününüzü çalabilir. Bu nedenle, tek bir veri bloğu içeren string’lerde bu flag'i açmamak genellikle daha iyidir.
m (multiline): Her bir satırı tek bir string değeri olarak ele almak için kullanılır.
i (insensitive): Büyük-küçük harf ayrımı yapmaz.
u (unicode): Türkçemizdeki ve diğer dillerdeki İngilizce harf dışındaki yazı karakterlerini A-Z alfa numerik karakterler ile bir tutar. Yani, eğer Türkçe bir veriyi temizliyorsanız, unicode flag'ini kullanmalısınız, aksi takdirde "ç" gibi karakterler düzgün bir şekilde eşleşmeyebilir. Bu flag, dil bağımsızlığı sağlar.
Buradan sonraki flag'leri kullanmanıza gerek yok, çünkü genellikle spesifik durumlar haricinde kullanılmazlar. Şimdi meta karakterlere geçelim.
Evet, sıra Regex'in içini doldurmaya geldi. Peki, ne ile dolduracağız? Meta karakterler ile... Buradaki "meta", gerçek olmayan, daha çok bir işaretleyici veya koşul anlamında kullanılır. Hadi bu karakterlere bir göz atalım!
.: Nokta karakteri, herhangi bir karakteri temsil eder. Diyelim ki, "dana mana bana" gibi bir metnimiz var ve bu metinlerin hepsini almak istiyoruz. İlk karaktere herhangi bir karakter olabileceğini ifade etmek için . kullanırız. Örneğin, ./ana/g() diyoruz.
(): Gruplama, bir veya birden fazla koşulu içeren karakter grubunu tek bir grup içine alır. Böylece bu karakter grubu, sanki tek bir karaktermiş gibi davranabilir. Örneğin, 4 adet herhangi bir karakterli değeri grup içine alalım: (....).
Bu ifadelerle, "dana", "mana" ve "bana" gibi metinleri içeren kısımları kolayca eşleştirebiliriz.

+: Kendinden bir sonraki karakter, kendisi ile aynı karakter ise veya izin verdiğimiz karakter grubu ise veya herhangi bir gruba aldığımız karakter grubu ise, bu durum false gelene kadar seçmeye devam eder. Ve bu seçtiği tüm karakterleri tek bir grup olarak sayar. Örneğin, 4 adet herhangi bir karakterli grubu, 4'er 4'er sonuna kadar birleşik halde alalım: (....)+.

?: Sonuna geldiği karakterin veya karakter grubunun olma zorunluluğunu kaldırır. Yani, "dana mana bana bela" içerikli string datamızda başında "lila" ifadesi olabilir, olursa onu da dahil et demek için /(lila)?(....)+/ diyebiliriz.
*: + ve ?'nin birleşimidir. Tebrikler, artık herhangi bir basit kelime grubunu hızlıca ayıklayabilirsiniz.
[]: Evet, nokta gibi düşünebilirsiniz ancak herhangi bir karakterden ziyade, bizim seçtiğimiz karakterlerle eşleşir (true eder). Örneğin, "dana hera bela" olan karakterlerden 2. karakteri "e" olan 4 haneli karakteri olan stringleri seçmek için /.(e..)+/g kullanabiliriz. Ancak bu arkadaşın özellikleri burada bitmiyor.
Köşeli parantezin içine, eğer a-z, A-Z, 0-9 gibi ifadeler yazar isek, alfa numeric harfleri ve rakamları da kapsar.
Not: İçindeki köşeli parantez içindeki her karakter, normal karakter sayar; sadece a-zA-Z0-9 hariç.
Diyelim ki, "mana bina bena" string değerinin 1. karakteri herhangi bir karakter, 2. karakter sadece "a" ve "e" harflerini kapsasın, diğer 2 karakterde "na" karakteri olsun. Bu durumu ifade etmek için /[ea]na/ kullanabiliriz.

[^]: Bu meta karakterimiz, içine dahil olduğu karakterler hariç diğer karakterleri seçmemize olanak tanır. Örneğin, "ana bina bena" string değerinin 1. karakteri herhangi bir karakter olabilir. 2. karakter ise "e" ve "a" harfleri hariç herhangi bir karakter olsun diyelim. Bu durumu ifade etmek için /(.[^ea]na)/g kullanabiliriz.
{}: Süslü parantezler, bir veya birden fazla veya sonsuz kez bir karakter veya karakter grubunu seçmemize olanak sağlar. Örneğin, sadece 3 adet rakam seçmek istiyorsak \d{3} yazmamız yeterli olacaktır. Ancak, diyelim ki en az 3 en fazla 11 adet word karakteri seçmek istiyoruz, o zaman \w{3,11} kullanabiliriz. Ya da en az 3 adet birbirleri ile yan yana yazılmış "yipyipyipyip..." kelimelerini sınırsızca seçmek istiyorsak, bu durumu ifade etmek için \w{3,} kullanabiliriz.

^: Sadece Regex'in başında veya bir grup başında kullanılabilen bir meta karakterdir. String datanın başındaki meta karakterlerin belirli bir durumu sağlamak üzere kullanılır. Örneğin, "RocknRoll" kelimesinin başındaki sadece ilk kelimeyi almak için kullanabiliriz ve bu kelimenin aynısını 3 satır alt alta yazdırmak istiyorsak /^\w+/g kullanabiliriz. Bu ifade, sadece en üst satırdaki ilk kelimeyi alır. Aynı işlemi tüm satırlar için yapmak istiyorsak /^\w+/mg kullanabiliriz.
$: Dolar meta karakteri ise string verinin sonunda belirli bir durumu kontrol etmek için kullanılır. Örneğin, "RocknRoll" kelimesinin sadece en son kelimesini almak istiyorsak, bu durumu ifade etmek için /\w+$/ kullanabiliriz.

|: "Veya" meta karakteri, bir veya birden fazla karakter grubu o koşulu karşılayabilir demek için kullanılır. Örneğin, "I love cats but hate snakes" string ifadesindeki "cats" veya "dogs" kelimesi gelse, bu ifadenin tamamını seçmek için /I love (cats|dogs) but hate snakes/g kullanabiliriz.
\: Backslash meta karakteri, özel meta karakterleri string data’nın içinde aramak için kullanılır. Örneğin, +, *, ? gibi özel meta karakterleri normal karakter olarak aramak için \? kullanabiliriz. Eğer özel bir meta karakter çağırmak istiyorsak (sadece yazılar, sadece sayılar gibi) bu meta karakterin yanına bir karakter ekleyerek çağırabiliriz. Ancak, bu özel meta karakterleri size göstereceğim. İlk önce, "https://app.patika" linkindeki "https://app.patika" kısmını alalım

\w: kelime meta karakteri A-Z a-z 0-9 ve _ arasındaki tüm karakterleri seçer.
/\w+/g
\W: kelime meta karakterinin tam tersi kelime olmayan karakterleri seçer.
/\W+/g
\d: sadece rakam olan karakteri seçer.
\D: rakam olmayan tüm karakterleri seçer.
\s: sadece boşluk olan karakterleri seçer.
\S: boşluk olmayan tüm karakterleri seçer.
Buraya kadar geldiğinize göre şöyle bir testi çözebilirsiniz :)
\b: Boundary (sınır) meta karakteri, yazdığımız ifadenin önüne geldiğinde, kendinden önceki ifadelerin bir word (\w) grubundan bir karakter olmaması gerektiğini söyler. Eğer ifadenin sonuna gelirse de, kendinden sonraki karakterin herhangi bir A-Za-z0-9 olmaması gerektiğini söyleriz.
Diyelim ki, "word boundaries are odd win to war happiness again" string verisindeki sonunda word karakteri olmayan "s" karakterlerini bulmak istiyoruz. Bu durumu ifade etmek için /s\b/g kullanabiliriz.


\B: Non-boundary (sınır olmayan) meta karakteri, boundary (\b)'nin tam anlamıyla tersidir. Herhangi bir word karakteri olmak zorundadır.
\K: Bu meta karakter, aradığımız string değer içindeki bir ifade veya grubu bulduktan sonra başlangıç noktamız string değerin başı yerine, bulduğumuz değerin sonu olur. Diyelim ki, "123,456,789" string verimizdeki ilk 3 rakamı bulduktan sonra diğer rakam ve virgülleri seçmek istiyoruz. Bu durumu ifade etmek için /^\d{3}\K[,0-9]+/g kullanabiliriz. Bu ifade, ilk üç rakamı bulur ve ardından gelen rakamları ve virgülleri seçer.

\1, \2: Backreference (geri referanslar) bir grubun aynı ifadesini çağırmak için kullanılır. İşe yarar çünkü herhangi xxx numaralı grubun aynısını koşula yazamadığımızda, ancak o koşulun aynısını referans ettiğimizde kullanılır. Bu meta karakterler, birbirini tekrar eden kelime grupları gibi nadir durumlarda çok etkilidir.
Diyelim ki bir HTML dosyasının içinden "Testing <B><I>bold italic</I></B> text." ifadesini çekmeye çalışıyorsunuz. İçerideki "bold italic" yazısının <b> ve <i> elementleri ile çekmeye çalışıyorsanız, bu durumu ifade etmek için /<(B|I)>(.*?)<\/\1>/g kullanabilirsiniz. Bu ifade, <B> veya <I> ile başlayan ve aynı etiket ile biten içerikleri seçer. Evet, başlangıçta zor olduğunu kabul etmek gerek…

Backslash'lı meta karakterleri de öğrendiğimize göre buraya şöyle bir test bırakalım.
Geldik parantezli meta karakterlere…
(?=...): Lookahead meta karakteri, kendisinden önceki kelimenin seçilmesi için önce bu meta karakterinin koşulunun (true) karşılanması gerektiğini belirtir. Diyelim ki, "foobar foobaz" string verisindeki "foo" kelimesini, ancak sonunda "baz" olan "foo" kelimesini almak istiyoruz. Bu durumu ifade etmek için /foo(?=bar)/g kullanabiliriz.

(?!...): Negative lookahead, lookahead'in tam tersidir. Diyelim ki, "foobar foobaz" string verisindeki "foo" kelimesini, ancak sonunda "baz" olmayan "foo" kelimesini almak istiyoruz. Bu durumu ifade etmek için /foo(?!bar)/ kullanabiliriz.
(?<=...): Lookbehind meta karakteri, bir karakter veya karakter grubunu almak istediğimizde, önünde şu karakter veya karakter grubu olmak zorunda demek istediğimiz zaman kullanılır. Diyelim ki, "foobar fuubar" string verimizdeki önünde "fuu" olan "bar" kelimesini almak istiyoruz. Bu durumu ifade etmek için /(?<=fuu)bar/ kullanabiliriz.
(?<!...): Negative lookbehind, lookbehind'ın tam tersidir. Diyelim ki, "foobar fuubar" string verimizdeki önünde "fuu" olmayan "bar" kelimesini almak istiyoruz. Bu durumu ifade etmek için /(?<!fuu)bar/ kullanabiliriz.

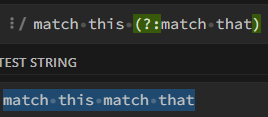
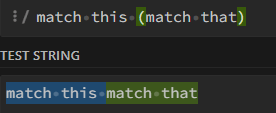
(?:...): Bu meta karakter, kendinden önce seçilmiş, eşleşmiş ve daha sonra tekrar grup içine alınacak eşleşmeleri birleştirir. Diyelim ki, "match this match that" stringindeki "match that" verisini bir gruba almak istiyoruz, ancak eşleşme sırasında "match this" ifadesi ile bir şekilde eşleşmesini sağlamak ve geri dönüş yapmasını istiyoruz. Bu durumu ifade etmek için /match this (?:match that)/g kullanabiliriz. Bu ifade, "match this" ile eşleşen ve ardından "match that" ile eşleşen kısmı bir grup içinde birleştirir.
(?<HelloWorld>..): Bu meta karakter, grupları isimlendirmek için kullanılır. Yani, yön parantezleri grubun başına yazılır ve içine bu gruba hangi adı vermek istiyorsak o adı yazabiliriz. Örneğin, bir 9 haneli sayıyı üç gruba ayırmak ve her birini ayrı ayrı grup halinde almak istiyorsak:
/(?<milyonlar>\d{3})[ ]?(?<binler>\d{3})[ ]?(?<yuzler>\d{3})/
Bu ifade, bir milyonlar grubu, bir binler grubu ve bir yüzler grubu oluşturur.
Aşağıda ise çok kullanılan örnekleri içeren regex ifadeleri bulunmaktadır:
Telefon numaralarını seçmek:
1234567890
123-456-7890
123 456 7890
(123) 456-7890
+1 123 456 7890
regex = /((?<area>\+\d{1,2})[ -])?\(?(?<operator>\d{3})\)?[ -]?(?<main>\d{3})[ -]?(?<number>\d{4})/gm
Tarih seçmek:
14/02/2018
14-02-2018
14.02.2018
14.02.18
regex= /(?<day>([0-9]{2}))([\/\-\.])(?<month>([0-9]{2}))([\/\-\.])(?<year>([0-9]{2,4}))/mg
Url secmek:
[https://www.patika.dev~reactogreninogretin]
[https://www.klasikyazilimci.com,php-oldu-abi-artik]
[https://www.youtube.com/kodluyoruz|patika youtube kanalı]
regex= /(?<url>(?<=\[)(.)(?=[~,\|]))[~|,|\|](?<title>(?<=[~|,|\|])(.)(?=\]))?/gm
Daha fazla örnek için codewars'ın regex testlerini çözebilirsiniz.
Patika+ ile yazılımı en iyi eğitmenlerle, iş hayatının birebir simülasyonu eşliğinde öğrenirsin. Şimdi başvur, yazılım kariyerine yaşın ne olursa olsun başla: https://www.patika.dev/patikaplus
Bu metni kaleme aldığı için Mehmet Yağız Maktav’a teşekkür ederiz. Öğrencimizin bloguna göz atabilirsiniz: https://academy.patika.dev/tr/blogs/detail/her-yazilimcinin-bir-gun-ihtiyaci-olan-sey-regex-nedir-


